
一、现状
近年来,随着深度学习技术的高速发展,语音方向由传统的信号处理逐步转向了深度神经网络的方法,其中,说话人声纹识别技术也日益进步。
经典的传统声纹识别使用 GMM-Universal Background Mode(GMM-UBM)的方法,通过非目标 数据训练通用模型,引入目标后,使用最大后验概率(MAP)自适应算法将模型进行调 整,生成 i-vector 特征。采用 Probabilistic Linear Discriminant Analysis (PLDA)的方法,对信道进行补偿。
随后,深度神经网络(DNN)的出现,逐渐取代了基于 GMM 的方法。
另一种方法是使用时延神经网络(TDNN)提取的 embeddings 特征,称为 x-vector。其中的 Statistics Pooling Layer,负责将 Frame-level Layer 映射到 Segment-Level Layer
快鱼电子声纹识别系统是快鱼电子自主研发、也集成了使用 GE2E 训练的长短期记忆 人工神经网络(LSTM)作为可选声纹特征提取器之一,提取说话人声纹特征。
可以对说话人进行身份验证的生物识别。可为用户提供离线、在线识别服务。同时支持包括Windows、Android、Ios平台设备的服务。系统的主要技术指标如下表所示:
| 快鱼声纹识别系统技术指标 | |
| 注册时间 | 文本相关:3S |
| 文本无关:10S | |
| 验证时间 | 文本相关:3S |
| 文本无关:10S | |
| 准确率 | 理论测试约可达95%准确率 |
| 等错误率 | 理论测试约<=5%准确率 |
| 方言支持 | 支持 |
| 多语种支持 | 支持 |
| 处理速度 | 10000次/秒 |
| 支持平台 | Windows、IOS、Android |
二、迭代版本
1、基于IVECTOR算法的声纹识别算法
该算法基于微软开源工具,在处理长语音(大于5S)的识别种有较好的效果,识别速度偏慢,计算一次IVECTOR特征大约需要500毫秒
2、基于DEEP-SPEAKER声纹识别的算法
该算法由百度提出,是一种基于端到端的声纹识别算法,骨干网络采用类似于resnet的残差结果,后端采用tirplet loss损失函数,该算法可处理段语音(2S)的声纹识别,等错误率大约为8%,识别速度大约为200毫秒。
3、基于BUT的声纹识别算法
该算法由voxcele竞赛冠军队伍提出,错误率大约为4%,识别速度大约为200毫秒
4、基于NFNET的声纹识别算法
该算法在BUT算法的基础上,该算法等错误率大约为4%,识别速度大约为100毫秒
5、基于EFFICIENTNETV2的声纹识别算法
该算法使用EFFICIENTNETV2作为骨干网络并作出一定的优化,该算法的等错误率大概为3%,识别速度大约为40毫秒。
三、声纹识别流程
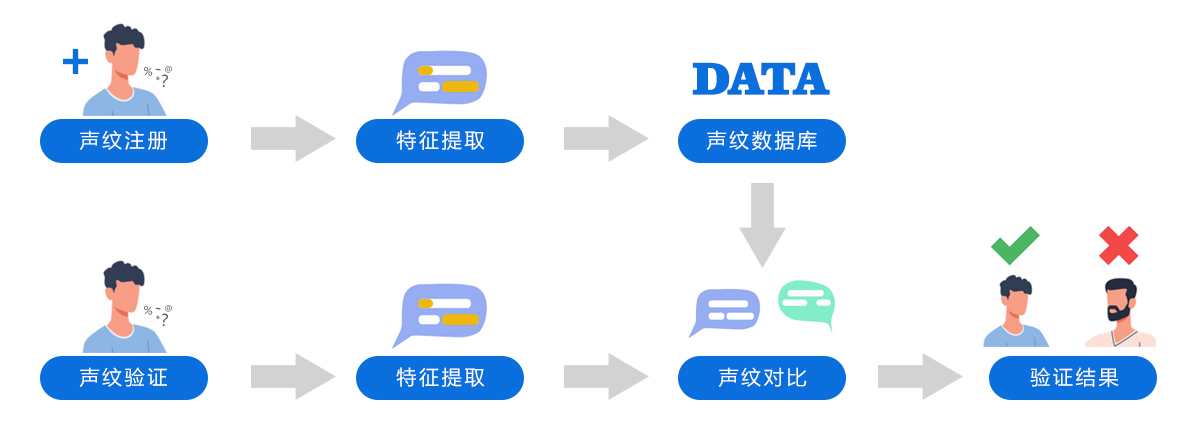
四、算法演示
快鱼电子声纹识别系统的核心任务是对说话人进行身份确认。具体可分为两类任务。
1、讲话人身份确认
当一个说话人自称是A用户时,我们需要确认这个人是否就是真的A用户。我们通过可以采集说话人声纹,与声纹库中已保存的说话人A的声纹进行对比,然后给出判定结果。
2、说话人身份检索
对说话人进行身份检索,即找出与已有声纹库中最相似的语音,从而判定该说话人最有可能的身份信息。